
Datenkompetenz ist eine Schlüsselqualifikation für Führungskräfte: Wer Analysen, Kennzahlen und Studienergebnisse fundiert beurteilen kann, trifft bessere Entscheidungen – und erkennt, wann Zahlen mehr suggerieren, als sie tatsächlich belegen. Dieser Kurs vermittelt die methodischen Grundlagen des datengestützten Arbeitens entlang des gesamten Analyseprozesses: von der Datenerhebung bis zum statistischen Modell. Nach Abschluss des Kurses können Sie empirische Studien und datenbasierte Argumente kritisch beurteilen, statistische Kennzahlen korrekt interpretieren, typische Fehlschlüsse im Umgang mit Daten erkennen und grundlegende statistische Modelle auf betriebswirtschaftliche Fragestellungen anwenden.
- Dozent/in: Christian Soost

Die Vorlesung führt in die Grundlagen der schließenden (induktiven) Statistik ein und behandelt zentrale Methoden zur quantitativen Analyse von Stichprobendaten. Aufbauend auf den Grundlagen der deskriptiven Statistik werden Verfahren vorgestellt, mit denen auf unbekannte Parameter einer Grundgesamtheit geschlossen und Hypothesen überprüft werden können. Inhalte sind unter anderem: Zufallsvariablen und Verteilungen, Schätzverfahren (Punkt- und Intervallschätzung), Hypothesentests für Mittelwerte, Varianzen und Anteile, lineare Regression, Korrelation sowie Varianzanalysen. Darüber hinaus werden moderne Ansätze der Randomisierung und Simulation behandelt, etwa Randomisierungstests, Bootstrap-Verfahren und Monte-Carlo-Simulationen, die ein tieferes Verständnis der statistischen Inferenz und ihrer Voraussetzungen ermöglichen.
- Dozent/in: Christian Soost
Die Vorlesung vermittelt die mathematischen Grundlagen, die für das Verständnis ökonomischer Modelle und quantitativer Analysen erforderlich sind. Behandelt werden zentrale Themen der Analysis, Linearen Algebra und Finanzmathematik mit wirtschaftswissenschaftlichen Anwendungsbezügen. Inhalte sind unter anderem: Funktionen und ihre Ableitungen, Elastizitäten, Extremwertprobleme, Gleichungen und Ungleichungen, Matrizenrechnung, lineare Gleichungssysteme, Zins- und Zinseszinsrechnung sowie Grundlagen der Optimierung. Ziel der Veranstaltung ist es, Studierenden ein solides mathematisches Fundament für weiterführende Fächer wie Statistik, Mikro- und Makroökonomie sowie Ökonometrie zu vermitteln und die Fähigkeit zu fördern, mathematische Methoden sicher auf wirtschaftliche Fragestellungen anzuwenden.
- Dozent/in: Juliana Leidig
- Dozent/in: Christian Soost
- Dozent/in: Sam Steinhöfer

Die Veranstaltung vermittelt vertiefte methodische Kompetenzen für die Planung, Durchführung und Auswertung empirischer Forschungsprojekte. Aufbauend auf vorhandenen Kenntnissen der Statistik und empirischen Sozialforschung werden zentrale Konzepte der Forschungslogik, Studiendesigns sowie der Messung und Operationalisierung theoretischer Konstrukte behandelt. Ein Schwerpunkt liegt auf der Auswahl geeigneter Methoden zur Beantwortung komplexer Forschungsfragen sowie auf der kritischen Bewertung empirischer Studien. Darüber hinaus werden fortgeschrittene Verfahren der Datenaufbereitung und -analyse eingeführt und anhand praktischer Anwendungen vertieft.
- Dozent/in: Christian Soost

In dieser Veranstaltung wird bereits erworbenes Wissen aus der Deskriptiven und Induktiven Statistik zu einem geringen Teil wieder aufgefrischt, ansonsten aber hauptsächlich vorausgesetzt. Darauf aufbauend wird sowohl die Theorie ausgebaut und erweitert, als auch das bereits vorhandene und hinzugewonnene Wissen in praktischen Anwendungen mit der Software R am Rechner umgesetzt. Den Teilnehmern dieser Veranstaltung wird ein solides Fundament zur Bearbeitung empirischer Problemstellungen vermittelt, das aber auch gleichzeitig als Basis für tiefer gehende quantitative Analysen dient.
- Dozent/in: Christian Soost
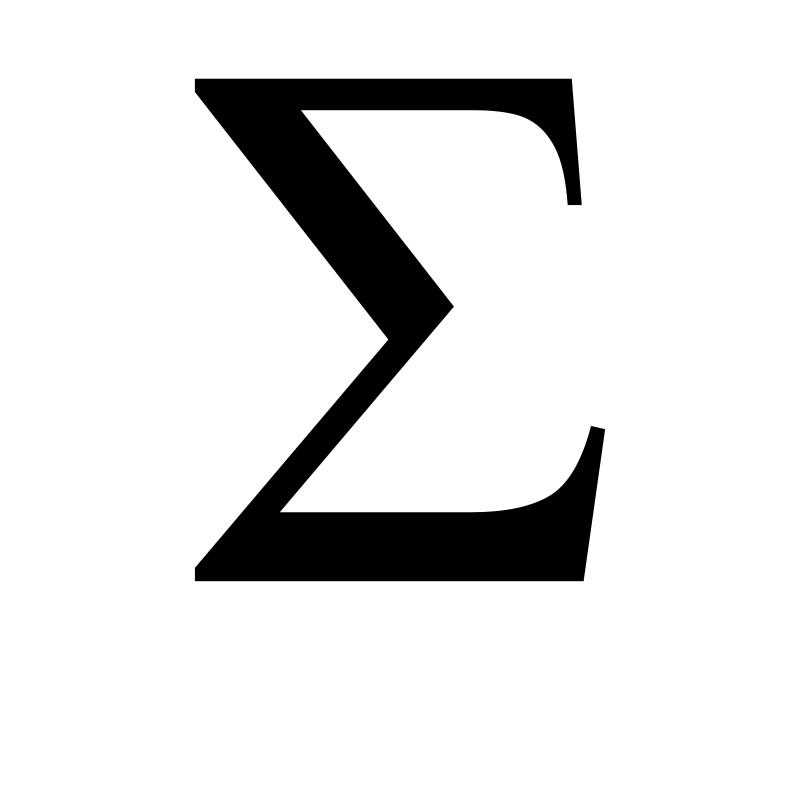
Das Fach Statistik lässt sich in die zwei Teilgebiete Deskriptive Statistik und Induktive Statistik aufteilen. Während die weiterführende Induktive Statistik sich im Wesentlichen mit Hypothesentests befasst, beinhaltet die Deskriptive Statistik die Aufbereitung, Analyse und graphische Darstellung von empirischen Daten. Diese durch Beobachtung, Messung oder Durchführung eines Experiments gewonnenen Datenmengen müssen in geeigneter Weise beschrieben und zusammengefasst werden. Das geschieht durch die Berechnung von Maßzahlen wie absolute und relative Häufigkeiten, Mittelwerten, Streuungs- und Konzentrationsmaßen und Indexzahlen; Konzepte, die im Rahmen der ersten Vorlesungen vorgestellt werden. Anschließend wird die Messung und Quantifizierung von Datenzusammenhängen durch Kovarianz und Korrelation sowie der Regressionsrechnung eingeführt und das Wesen der Zeitreihenanalyse dargestellt. In den zwei abschließenden Vorlesungen wird eine Einführung in die Wahrscheinlichkeitsrechnung behandelt, die neben vielen weiteren sinnvollen Anwendungen auch zur Vorbereitung auf die Induktive Statistik dient.
- Dozent/in: Christian Soost